
Cybernetics and Systems Analysis, Vol. 49,
No.
2, March, 2013
ROBUST IDENTIFICATION OF NONLINEAR
OBJECTS WITH THE HELP OF AN EVOLVING
RADIAL BASIS NETWORK
O. G. Rudenko,
a†
O. O. Bezsonov,
a‡
and S. O. Rudenko
a†
UDC 519.71
Abstract. The problem of neural network-based robust identification of nonlinear dynamic objects in
the presence of non-Gaussian noise is considered. To solve this problem, a radial basis network was
chosen whose structure is specified and training is provided with the help of a genetic algorithm. The
simulation results are presented that confirm the efficiency of the proposed approach.
Keywords: neural network, training, identification, evolutionary algorithm, robustness.
INTRODUCTION
The problem of obtaining mathematical models that describe real objects and adequately represent their properties is
not only of interest in itself but also is an integral part of the problem of optimization of functioning definite objects (their
control, behavior prediction, etc.). The main difficulties in obtaining a high-quality solution to an identification problem are
conditioned by the nonlinearity and nonstationarity of characteristics of objects being investigated, presence of various
noises, and absence of sufficient a priori information on the objects themselves and their functioning conditions. Whereas
the theory of identification of linear stationary objects is developed rather thoroughly, nonlinear objects are mostly identified
subjectively using mainly the approximation of nonlinearities by various series (Volterra, Hammerstein, Wiener, etc.) or
polynomials. However, these classical models are nonparametric, which considerably complicates the solution of
identification problems.
Difficulties connected with the identification of nonlinear dynamic objects by traditional methods have led to the
appearance and development of an alternative neural network-based approach to the solution of this problem. Since, from
the mathematical viewpoint, the identification problem is the problem of approximation (or recovery) of some nonlinear
function that is complicated in general form, to solve the problem, artificial neural networks (ANNs) are used that are
formed by neurons with nonlinear activation functions and are good approximators.
It should be noted that, in investigating nonlinear objects with the help of ANNs, a fundamental role is played by
objects of the form NARMAX (Nonlinear Auto-Regressive Moving Average with eXogeneous inputs) or NARX (Nonlinear
Auto-Regressive eXogeneous with inputs) models that are, respectively, of the form [1–3]
yk f yk yk K uk uk K
yu
( ) [ ( ),..., ( ), ( ),..., ( ),=- - - -11
xx x
x
( ),..., ( )] ( )kkKk--+1
, (1)
yk f yk yk K uk uk K k
yu
( ) [ ( ),..., ( ), ( ),..., ( )] ( )=- - - -+11x
, (2)
where
yi()
and
ui()
are output and input signals, respectively,
K
y
,
K
u
, and
K
x
are orders of lag for the output and
input signals of the object and noise, respectively,
f[•]
is a nonlinear function, and
x()k
is noise.
For models (1) and (2), the identification problem consists of obtaining an estimate for the function
f[•]
from the
results of measurements of input and output variables.
173
1060-0396/13/4902-0173
©
2013 Springer Science+Business Media New York
a
Kharkov National University of Radio Electronics, Kharkiv, Ukraine,
†
‡
[email protected]. Translated from Kibernetika i Sistemnyi Analiz, No. 2, pp. 15–26, March–April 2013. Original
article submitted January 15, 2012.

By analogy with the traditional approach to the solution of the identification problem in which the process of
constructing a model is subdivided into two stages, namely, structural and parametric identifications, the application of
ANNs also requires the solution of two problems, namely, the determination of the structure of a network and adjustment of
its parameters by training.
The simplicity of structures of radial basis networks (RBNs) and the presence of many algorithms for training them
have provided their wide application in identifying nonlinear dynamic objects [4–9].
STRUCTURE OF AN RBN
An RBN has a two-layer structure. The hidden layer consists of neurons each of which calculates some distance
between its center
m
and the input vector
x()k
of the network. Below, the NARX model is used for which
x ( ) [ ( ), ( ),..., ( ), ( ), ( ),...,kyk yk ykKuk uk
y
=- - - - -12 12uk K
u
T
()]-
.
Then each neuron of the hidden layer transforms the result obtained with the help of a definite nonlinear basis function (BF)
F
i
kf( ( ), , ) (|| ||, )xxWWss=-
(here,
s
is the radius of the BF).
A model represented by a radial basis network is of the form
$
[] ((),, )yk a w k
ii
i
N
=+
=
å
0
1
F x W s
,
(3)
where
a
0
is a bias of a neuron of the output layer,
w
i
is the weight of the connection of the
i
th neuron of the hidden
layer with a neuron of the output layer, and
N
is the number of neurons in the hidden layer.
The functions presented in Table 1 are most often chosen in the capacity of BFs.
The question of choosing the structure of an RBN (the number and types of basis functions of individual neurons) is
supremely important since it determines both the accuracy and complexity of solution of the problem stated. At the present
time, unified or at least sufficiently efficient methodologies for determining network structures are absent and, therefore, the
choice of the topology of a network is empirical and based on the experience of the designer. Whereas a successive
complication of the structure of an RBN by introducing a new neuron on the basis of a definite criterion was considered in
174
TABLE 1
Function
Number
Function Name Function Type
1 Gaussian
F() exp
()
x
x
=-
-
ì
í
ï
î
ï
ü
ý
ï
þ
ï
m
s
2
2
2 “Mexican Hat”
F()
()
()
x
x
e
x
=-
-
æ
è
ç
ç
ö
ø
÷
÷
-
-
1
2
2
2
2
m
s
m
s
3 Laplace
F() exp
||
x
x
=-
-
ì
í
î
ü
ý
þ
m
s
4 Rayleigh
F()
()
exp
()
x
xx
=
-
-
-
ì
í
ï
î
ï
ü
ý
ï
þ
ï
2
2
2
m
s
m
s
5 Generalized Gaussian
F()
() ()
x =
-- -
-
e
T
Rxxmm
1
, where
RrijLkN
ij
k-
===
1
11[],, ,, ,
,
is a scaling matrix (
L
is the dimensionality of the input signal,
and
N
is the number of neurons)
6 Cosine
F()
()
x
x
=
-
ì
í
î
ü
ý
þ
cos
2pm
s
7 Parabolic
F()
()
x
x
=-
-
1
2
2
m
s

[10, 11], the evolutionary approach based on the genetic algorithm (GA) was used later on in many publications (see, for
example, the bibliographies in [12–14]) to determine the structure of a network.
TRADITIONAL TRAINING OF RADIAL BASIS NETWORKS
The training of an RBN using the basis functions presented in Table 1 consists of the determination of the vector of
parameters of the hidden layer
qs= (,,,)a
T
0
w W
from training pairs
{}x (),(), ,,kyk k=12K
, presented to the network.
In choosing the criterion
F
k
ei
k
i
K
() ((,))qrq=
=
å
1
1
, (4)
where
rq((, ))ei
is some loss function and
ei yi yi(, ) ()
$
(, )qq=-
is an error, the training is reduced to searching for an
estimate
$
min ( )qq
q
kk
F=arg
determined as a solution to the system of equations
Ñ=
¶
¶
=
¶
¶
=
=
å
F
F
ei
ei
j
j
i
K
j
()
()
((, ))
(, )
.q
q
q
yq
q
q
1
0
(5)
Here,
yq
rq
q
((, ))
((, ))
(, )
ei
ei
ei
=
¶
¶
is an influence function.
At present, the majority of training algorithms are based on the hypothesis that the noise distribution
x
obeys the
normal law; these algorithms are various modifications of the least squares method (LSM) minimizing the quadratic loss
function
rq((, ))ei
and providing, under these conditions, an asymptotically optimal solution with a minimal dispersion in the
class of unbiased estimates.
If noise is not normally distributed and has spikes or long “tails,” then an LSM estimate turns out to be unstable, and
it is precisely this fact that became the precondition for the development of an alternative such as robust estimation in
statistics with a view to preventing the influence of great errors.
Among the three basic types of robust estimates, namely, M-, L-, and R-estimates that are, respectively, maximum
likelihood estimates, linear combinations of order statistics, and estimates obtained in rank criteria, M-estimates [15]
proposed by P. Huber are mostly used in training problems.
An M-estimate also is an estimate
$
q
determined as a solution of extremal problem (4) or as a solution to the system of
Eqs. (5), but a nonquadratic function is chosen in the capacity of the loss function
r()e
i
. An investigation of different
classes of noise distributions made it possible to obtain least favorable distributions (i.e., distributions minimizing Fisher’s
information) for these classes, and the use of these distributions, in turn, determines the type of a loss function and provides
the obtaining robust estimates suitable practically for any noise distributions.
Classical robust methods are oriented towards the symmetry of contamination when spikes occur equally frequently in
the intervals of negative and positive values. Robust training algorithms for RBNs are considered in [17–22].
The mentioned methods allow one to efficiently struggle against the noise described by the Tukey–Huber model [15, 16]
rx er x e x() ( ) () (),=- +1
0
q
(6)
where
rx
0
()
is the density of the corresponding basic distribution,
q()x
is the density of the contaminating distribution,
and
e Î[,]01
is a parameter describing the contamination level of the basic distribution. In this case, the basic and
contaminating distributions are Gaussian with zero expectations and dispersions
s
1
2
and
s
2
2
,
ss
1
2
2
2
<<
.
In a more general situation when the kind of contamination is arbitrary, for example, when the contaminating Gaussian
distribution has a nonzero expectation or this distribution is asymmetrical (the Rayleigh, logarithmically normal, Gamma,
Weibull–Gnedenko, etc. distributions), the estimates obtained on the basis of these methods are biased. The necessity of taking
into account the asymmetry of distributions stipulates the expediency of choosing asymmetric functionals [23].
Thus, although a sufficiently large number of algorithms for adjusting network parameters are developed and
well-studied at the present time, the choice of an optimal adjustment structure remains an open question.
175

NEUROEVOLUTIONARY ALGORITHM FOR TRAINING RADIAL BASIS NETWORKS
Algorithms that use models of mechanisms of natural evolution are usually called evolutionary algorithms. There are many
versions of such algorithms that differ in ways of using definite mechanisms and also in forms of representing individuals. The
totality of the most widespread types of evolutionary algorithms includes the genetic algorithms proposed J. Holland.
In a GA, each individual is coded by a method similar to that used in DNA cells, i.e., in the form of a string
(chromosome) containing a definite collection of genes. The length of a chromosome is constant. A population consisting of
some number of individuals is subjected to the process of evolution using the crossover and mutation operations.
The classical GA contains the following steps.
1. Creation of an initial population.
1.1. Initialization of the chromosome of each individual.
1.2. Estimation of the initial population.
2. Stage of evolution (construction of a new generation).
2.1. Selection of candidates for crossover (selection).
2.2. Crossover, i.e., the generation of new individuals
by each pair of selected candidates.
2.3. Mutation.
2.4. Estimation of the new population.
3. Check the termination criterion; if it is not satisfied, then go to item 2.
At the beginning of the execution of the neuroevolutionary algorithm, a population
P
0
is randomly initialized that
consists of
S
individuals (RBN networks),
PHH H
S012
={},,,K
. At the same time, each individual in the population
obtains its unique description coded in a chromosome
Hhh h
jjj Lj
={}
12
,,,K
consisting of
L
genes, where
hw w
ij
Î[, ]
min max
is the value of the
i
th gene of the
j
th chromosome
(
min
w
and
w
max
are minimal and maximal admissible
values, respectively). The format of a chromosome and the correspondence between genes and RBN parameters are
presented in Fig. 1. Here,
ñ
1
and
ñ
2
are expectations of the basic and contaminating noises, respectively, and
s
1
and
s
2
are
dispersions of the basic and contaminating noises, respectively. It should be noted that the length of a chromosome is
constant and is bounded by a maximally admissible number of neurons.
As is easily seen from Fig. 1, each chromosome consists of genes that store information on the corresponding
network parameters. The initial genes of a chromosome store information on noise parameters and are active only in the case
of identification of noisy objects. The next gene codes information on the parameter
a
0
, i.e., the bias of a neuron of the
output layer of the network. Then the blocks of the genes coding parameters of the corresponding neurons of the hidden
layer are located. The first gene of each of such a block (1/0) determines the presence of the corresponding neuron in the
network structure, i.e., its participation (or nonparticipation) in computing the output reaction of the network to the arrived
input signal. The gene BF determines the type of the basis function that belongs to a given collection of BFs and is used for
computing the reaction of the neuron.
Further, the chromosome contains a group of genes that directly code the following parameters of the corresponding neuron:
its weight parameter
w
, basis function center
m
,andtheradius
s
of the basis function. Note that the number of these parameters and,
hence, the chromosome length depends on the dimensionality of the object being identified. At the stage of initialization, initial
values from some admissible range are assigned to these parameters with the help of a random-number generator.
ESTIMATION OF A POPULATION
After the formation of the initial population, the fitness of each individual belonging to the population is estimated
proceeding from the analysis of its fitness function. As such a function, we use the following function in the case of offline
training in the presence of a complete sample of input-output object signals:
fx
M
yx yx
ij jj jj
j
M
() | ()
$
()|
*
=-
=
å
1
1
, (7)
where
yk
*
()
is a desirable network reaction,
$
()yk
is a real output signal, and M is the sample size.
176
General Network Parameters The
i
th Neuron
s
1
s
2
c
1
c
2
a
0
···
1/0
BF
w
i
m
i
s
i
···
Fig. 1

To simplify subsequent operations of sorting a population, the fitness function is usually normalized as follows:
fx
fx
fx
i
N
j
ij
jj
j
N
()
()
()
=
=
å
1
. (8)
Note that, to ensure the robustness of an obtained solution, a nonquadratic loss function
rq(, )i
used in M-training
RBNs can be used as a fitness-function. In this case, noise parameters need not be estimated to eliminate the bias of the
solution obtained, and the structure of the chromosome assumes the form shown in Fig. 2.
Thus, to determine the fitness of a network, it is necessary to simulate it using the entire sample and then to compare
network reactions with the real output signal of the object.
SELECTION
After computing the fitness function of each individual (network) in a population, the individuals whose
chromosomes will participate in the formation of a new generation should be selected. To this end, the following average
value of the fitness-function
f
av
is computed for the population as the arithmetic mean of values of the fitness-functions of
all individuals belonging to it:
f
N
f
i
j
N
av
=
=
å
1
1
.
Then the following ratio is calculated for each individual:
Pj
f
f
s
i
()=
av
,
and, depending on the value of
Pj
s
()
, the array of individuals whose chromosomes will participate in crossover is
formed.
Selection with the use of a threshold fitness function value can also be performed. In this case, individuals are sorted
in decreasing order of the normalized value of fitness function (8) and a threshold
q Î[,]01
is specified. For the crossover
procedure, only the individuals are selected for which the condition
f
i
£ q
is fulfilled.
CROSSOVER
After selecting parents by a selection method, they are crossovered. Crossover is used with a view to reproducing
descendants to interchange genetic information between parents. Let parents be described by the expressions
Hh h h
i
L
() () () ()
,, ,,
1
1
111
={}KK
;
Hh h h
i
L
() () () ()
,, ,,
2
1
222
={}KK
,
and let their descendants be described as follows:
Yy y y
i
L
() () () ()
,, ,,
1
1
111
={}KK
;
Yy y y
i
L
() () () ()
,, ,,
2
1
222
={}KK
.
The number of parents and descendants depends on the choice of a crossover operator and can vary. At the present
time, there are a rather large number of different crossover operators, for example, n-point, homogeneous, uniform,
177
The
i
th Neuron
a
0
···
1/0
BF
w
i
m
i
s
i
···
Fig. 2

comparative, diagonal, fuzzy, etc. The simplest operator used in this article is the one-point crossover operator owing to
which two parents
H
()1
and
H
()2
form chromosomes of two descendants as follows:
Yh hh h
i
iL
() () () ( ) ( )
,..., , ,...,
1
1
11
1
22
=
+
{}
,
Yh hh h
i
iL
() () () () ()
,..., , ,...,
2
1
22
1
11
=
+
{}
,
where
i
is a random quantity lying in the interval
[, ]1 L
.
MUTATION
Mutation makes it possible to create a new genetic material in a population to provide its variety. Mutation is neither
more nor less than a change in a random part of the chromosome representing a separate individual. The number of
mutations in a population is regulated by the parameter
p
m
that determines the probability of a mutation. Thus, only
pN
m
´
random chromosomes in a population can mutate.
The mutation operator performs possible mutations in definite genes of some chromosome. If the chromosome is of
the following form before a mutation:
Hh h h
jjijLj
={}
1
,..., ,...,
,
where
h
ij
is the gene that must mutate, then, after its mutation, it can be written as follows:
¢
=
¢
Hh h h
jjijLj
{}
1
,..., ,...,
.
In this article, a non-uniform mutation is used in which a gene
¢
h
ij
is created from a gene
hhh
ij
Î[, ]
min max
, where
h
min
and
h
max
are minimal and maximal admissible values for this gene, as follows:
¢
=
+-=
-- =
h
hkhh
hkhh
ij
ij ij
ij ij
D
D
(, )
(, )
max
min
if 0;
if 1
t
t ,
ì
í
ï
î
ï
where
t
is a uniformly distributed binary random quantity. The value of the function
D
is calculated by the formula
D(, ) ( ),ky y
k
T
b
=-
-
æ
è
ç
ö
ø
÷
1
1
a
where
a
is a random quantity uniformly distributed over the interval
[,]01
,
T
is the maximal number of iterations of the
algorithm,
k
is the current iteration, and
b
is the parameter determining the degree of non-uniformity of the distribution.
The operator
D(, )ky
can assume values in the range
[, ]0 y
, and the probability that this value tends to zero increases
with increasing
k
. Thus, at the initial stage of execution of the GA, a non-uniform mutation makes it possible to essentially
change the value of a mutated gene, and, at subsequent stages, only small refining mutations are performed that make it
possible to increase the accuracy of the already obtained solution.
Note that the non-uniform mutation method is used only for genes coding network parameters. For genes responsible
for the activation of neurons and the type of a basis function, the following random replacement is used:
hhh
ij
= rand [ , ],
min max
where
rand [ , ]xy
is a random integer uniformly distributed in an interval
[, ]xy
. In particular, for the gene responsible
for the activation of a neuron,
xy==01and
and, for a gene determining the type of a basis function,
xyP==1and
,
where
P
is the number of basis functions being used.
It should be noted that, on the one hand, mutations can lead to a worsening of the fitness of a given individual and, on
the other hand, a mutation is a unique mechanism of introducing new information in its chromosome.
178
SIMULATION
Experiment 1. The following nonlinear stationary object was identified:
yk
uk yk
uk yk
() .
() ()
() ()
=
-+ -
+-+-
æ
è
0725
16 1 8 1
34 1 4 1
22
sin
ç
ç
ö
ø
÷
÷
+-+ -+02 1 0 2 1.( ) . ( ) ()uk yk kx
(9)
in the presence of noise
x()k
described by the following model:
xee() ( ) () ()kqkqk=- +1
12
, (10)
where
e = 01.
and
qk
1
()
and
qk
2
()
are normally distributed noises with expectations
mm
12
0==
and dispersions
s
1
=0.6
and
s
2
= 12, respectively.
To correct the results, which is connected with the necessity of eliminating a bias caused by the action of noise (10),
the parameters of noises are estimated in [21–23] with the help of recurrent algorithms. In this experiment, to estimate noise
model parameters of object (9) in the chromosome coding the structure of an RBN, four additional genes (see Fig. 1) were
used that store the parameters
s
1
and
s
2
(estimates of
s
1
and
s
2
) and
c
1
and
c
2
(estimates of
m
1
and
m
2
). Fitness
function (7) was also modified as follows:
f
M
yx yx c
yx yx c
i
jj jj
jj jj
=
--
--£
1
1
1
2
1
*
*
()
$
()
()
$
()
s
sif 3
1
1
2
2
2
1
1
;
()
$
()
*
j
M
jj jj
j
M
M
yx yx c
=
=
å
å
--
ì
í
ï
ï
ï
s
otherwise.
î
ï
ï
ï
(11)
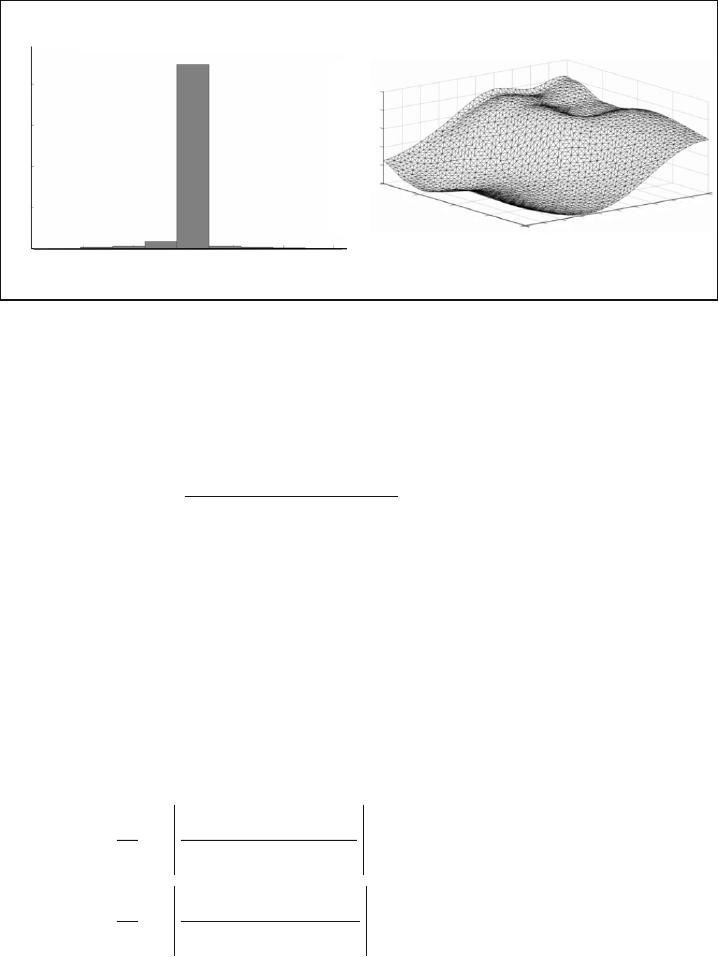
The results of identification of object (9) under noise conditions (10) are presented in Fig. 3. The figure presents the
noise histogram (Fig. 3a) and restored surface (Fig. 3b). After 2000 training epoches, the following estimates for noise
parameters were obtained:
s
1
05860= .
;
s
2
12 5818= .
;
c
1
00333= .
;
c
2
01646=- .
. The network consisted of 13 neurons
(seven neurons with BFs of the form (5) and six neurons with BFs of the form (6)).
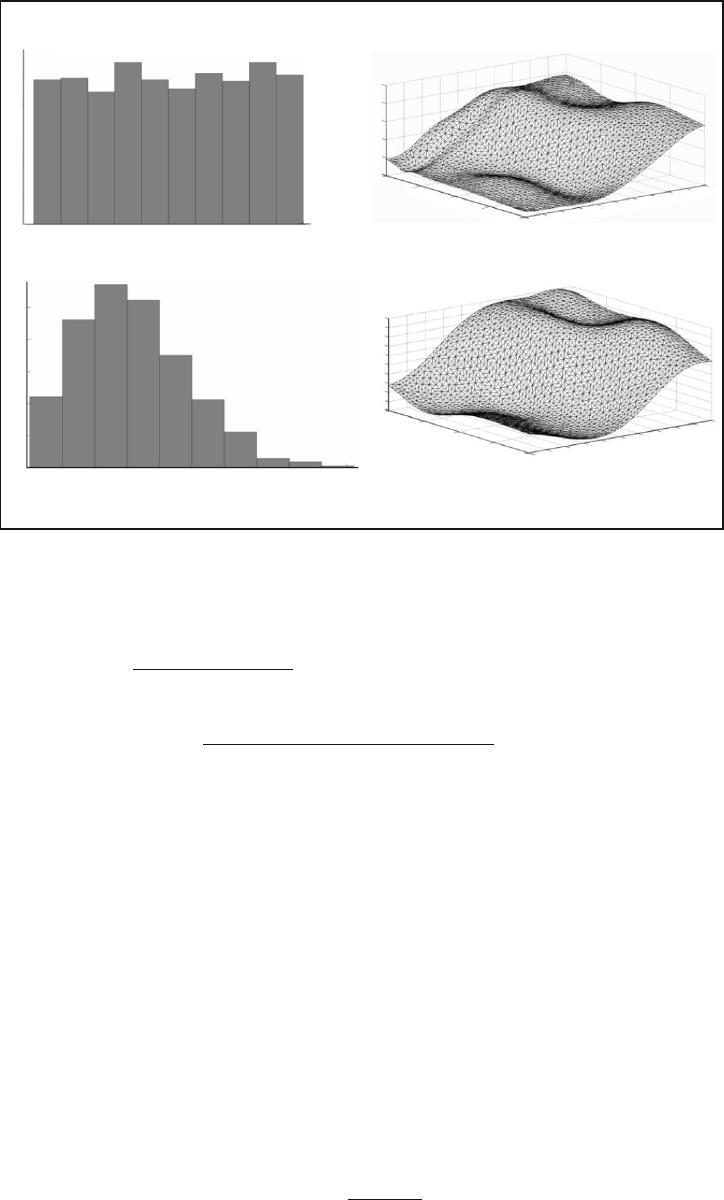
Experiment 2. The problem of identification of object (9) was considered in the presence of noise
x()k
uniformly
distributed according to the Rayleigh distribution (Ray (1.6)). In Figs. 4a and 4b, the noise histograms and forms of restored
surfaces, respectively, are presented.
Assuming that the real noise distribution is unknown, noise distributions in this experiment were approximated by
the Tukey–Huber model (10), which is used in [21, 22] and in which both the basic and contaminating distributions are
normal with estimates
m
1
,
m
2
0¹
. As a result of RBN training, the following contaminating noise parameters for the
uniform distribution were obtained:
s
1
=12.60
,
s
2
=1.83
,
c
1
0=
, and
c
2
=-0.17
, and, for the Rayleigh distribution, the
parameters were as follows:
s
1
0 9981= .
,
s
2
08555= .
,
m
1
1 9702= .
, and
m
2
5 2842= .
; these estimates were used for
correcting output signals of the network. In this case, the network consisted of 14 neurons (five neurons with BFs of the
form (5) and nine neurons with BFs of the form (6)).
179
Fig. 3
–1
– 0.5
2500
2000
1500
1000
500
0
– 30 – 20 –10 0 10 20
Number of Noise Measurements
z in an Interval
Intervals
ab
1.5
1
0.5
0
– 0.5
–1
0
0.5
1
0
– 0.4
0.4
1
yk()
yk()- 1
uk()- 1
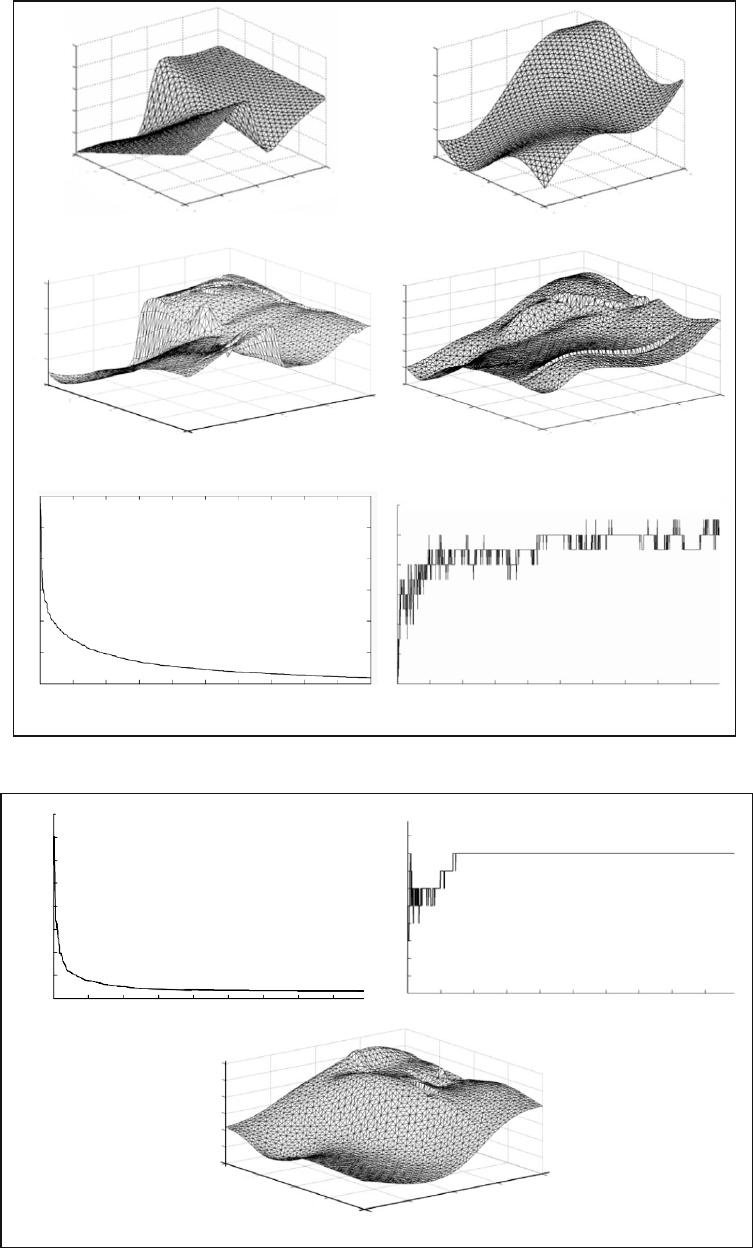
Experiment 3. The identification problem was solved for a multidimensional object (MIMO) described by the
following equations:
yk
uk y k
uk
uk
1
12
1
2
1
15 1 1
250 1
05 1 0()
()()
[( )]
.( ).=
--
+-
+--25 1 0 1
21
yk k(). ();-+ +x
yk
uk yk uk
k
2
21 2
2
1121
3
()
(()()) ()
(),=
--+-
+
sin p
x
(12)
where
u
1
and
u
2
are input signals,
y
1
and
y
2
are output signals, and
x
1
and
x
2
are measurement noises.
The noise
x
1
was described by model (10) with the same parameters as in Experiment 1. The noise
x
2
has the
Rayleigh distribution (Ray (1.6)). Thus, the output signals of the object were subjected to different noises. Moreover, since
this object is multiconnected, the final kinds of distributions are very difficult to determine. After 2000 training epoches, the
following estimates for the noise parameters (for each separate output of the object) were obtained:
s
1
1
=1.2042
,
s
2
1
= 7.4612
,
m
1
1
00= .
, and
m
2
1
= 0.6765
for the first output and
s
1
2
= 2.5593
,
s
2
2
=1.5492
,
m
1
2
00= .
, and
m
2
2
= 2.0294
for the
second output.
The network consisted of 17 neurons (nine neurons with the BF whose number equals 1 and eight neurons with the
BF whose number equals 2 in Table 1). The simulation results are presented in Fig. 5. Figures 5a, 5b, 5c, and 5d present,
respectively, the reference surfaces described by expressions, restored surfaces, curve of changing the value of the fitness
function of the winner, and curve of changing the number of active neurons of the winner.
Experiment 4. Object (9) was identified with the same noise parameters as in Experiment 1 using the fitness-function
of the form (7) and the functional
r
specified by the expression
r[( )]
()
()
ek
ek
ek
=
+
2
2
1
. (13)
Figures 6a and 6b present, respectively, the curve of changing the value of fitness-function (7) for the winner and the
curve of changing the number of active neurons. The restored surface is presented in Fig. 6c. The simulation results testify
that the use of fitness-function (7) with functional (13) allows one to efficiently eliminate noise using a simpler chromosome
format.
180
Fig. 4
–1
– 0.5
300
250
200
150
100
50
0
– 0,8 – 0,6 – 0,4 – 0,2 0 0,2 0 ,4 0,6
Number of Noise Measurements z
in an Interval
Intervals
1.5
1
0.5
0
– 0.5
–1
0
0.5
1
0
– 0.4
0.4
1
yk()
yk()- 1
uk()- 1
–1
– 0.5
600
500
400
300
200
100
012345
Intervals
ab
1
0.8
0.6
0.4
0.2
0
– 0.2
– 0.4
– 0.6
– 0.8
–1
0
0.5
1
0
– 0.4
0.4
1
yk()- 1
uk()- 1
181
Fig. 5
–1
– 0.5
0
0.5
0
– 0.5
0.5
1
yk
2
()
yk
1
1()-
uk
2
()
–1
– 0,5
Number
of Epochs
a
b
1.5
1
0.5
0
– 0.5
–1
–
– 1.5
0
0.5
1
0
– 0.5
0.5
1
yk
2
()
yk
1
1()-
uk
2
()
1.5
1
0.5
0
– 0.5
–1
–1
– 0,5
0
0,5
1
0
– 0,5
0,5
1
yk
1
()
yk
2
1()-
uk
1
()
1
140
120
100
80
60
40
20
0 200 400 600 800 1000 1200 1400 1600 1800
c
f
d
1
0.5
0
– 0.5
–1
–1
– 0.5
0
0.5
1
0
– 0.5
0.5
yk
1
()
yk
2
1()-
uk
1
()
1
N
0 200 400 600 800 1000 1200 1400 1600 1800
20
18
16
14
12
10
8
1
0.5
0
– 0.5
–1
Fig. 6
23.5
23
22.5
22
21.5
21
20.5
20
19.5
0 100 200 300 400 500 600 700 800
f
Number
of Epochs
–1
– 0.5
b
c
0
0.5
0
– 0.5
0.5
1
yk()
yk()- 1
uk()- 1
a
0 100 200 300 400 500 600 700 800 900
15
14
13
12
11
10
9
8
7
6
5
–1
N
CONCLUSIONS
As is obvious from the simulation results, an evolving RBN using the GA for the specification of the structure of
a neural network-based model and estimation of its parameters has a high degree of robustness and is capable of solving the
identification problem for strongly noisy objects. Two approaches to the elimination of the influence of noise are possible in
this case. The first is based on the use of the Tukey–Huber model and consists of estimating noise parameters, and the
second approach is based on the use of M-training and allows one to somewhat simplify the structure of a chromosome since
it does not require any store for additional parameters. The simulation results demonstrate the efficiency of both approaches.
REFERENCES
1. I. J. Leontaritis and S. A. Billings, “Input-output parametric models for non-linear systems. Part I: Deterministic
non-linear systems,” Inf. J. of Control., 41, 303–308 (1985).
2. I. J. Leontaritis and S. A. Billings, “Input-output parametric models for non-linear systems. Part II: Stochastic
non-linear systems,” Int. J. of Control, 41, 309–344 (1985).
3. S. Chen and S. A. Billings, “Representations of nonlinear systems: The NARMAX model,” Int. J. of Control, 49(3),
1013–1032 (1983).
4. K. S. Narendra and K. Parthasarathy, “Identification and control of dynamical systems using neural networks,” IEEE
Trans. on Neural Networks, 1, No. 1, 4–26 (1990).
5. S. Chen, S. A. Billings, and P. M. Grant, “Recursive hybrid algorithm for non-linear system identification using radial
basis function networks,” Int. J. of Control., 55, 1051–1070 (1992).
6. S. Khaikin, Neural Networks: A Complete Course [in Russian], Izd. Dom “Williams,” Moscow (2006).
7. J. T. Spooner and K. M. Passino, “Decentralized adaptive control of nonlinear systems using radial basis neural
networks,” IEEE Trans. on Automatic Control, 44, No. 11, 2050–2057 (1999).
8. R. J. Shilling, J. J. Carroll, and A. F. Al-Ajlouni, “Approximation of nonlinear systems with radial basis function
neural networks,” IEEE Trans. on Neural Networks, 12, No. 6, 1–15 (2001).
9. O. G. Rudenko and A. A. Bessonov, “Real-time identification of nonlinear time-varying systems using radial basis
function network,” Cybernetics and Systems Analysis, 39, No. 6, 927–934 (2003).
10. Y. Li, N. Sundararajan, and P. Saratchandran, “Analysis of minimal radial basis function network algorithm for
real-time identification of nonlinear dynamic systems,” IEEE Proc., Control Theory Appl., 147, No. 4, 476–484 (2000).
11. D. L. Yu and D. W. Yu, “A new structure adaptation algorithm for RBF networks and its application,” Neural
Comput. & Appl., 16, 91–100 (2007).
12. E. P. Maillard and D. Gueriot, “RBF neural network, basis functions and genetic algorithm,” in: Proc. Int. Conf. on
Neural Networks, 4, Houston, TX (1997), pp. 2187–2192.
13. S. Ding, L. Xu, and H. Zhu, “Studies on optimization algorithms for some artificial neural networks based on genetic
algorithm (GA),” J. Computers, 6, No. 5, 939–946 (2011).
14. O. Buchtala, M. Klimek, and B. Sick, “Evolutionary optimization of radial basis function classifiers for data mining
applications,” IEEE Trans. on Systems, Man, and Cybernetics, Part B, 35, No. 5, 928–947 (2005).
15. P. Huber, Robustness in Statistics [Russian translation], Mir, Moscow (1984).
16. F. R. Hampel, E. M. Ronchetti, P. J. Rousseeuw, and W. A. Stahel, Robust Statistics: The approach Based on
Influence Functions, Wiley, N.Y. (1986).
17. D. S. Chen, and R. C. Jain, “A robust back-propagation learning algorithm for function approximation,” IEEE Trans.
on Neural Networks, 5, 467–479 (1994).
18. K. Liano, “A robust approach to supervised learning in neural network,” in: Proc. ICNN, 1 (1994), pp. 513–516.
19. Ch.-Ch. Lee, P.-Ch. Chung, J.-R. Tsai, and Ch.-I. Chang, “Robust radial basis function neural networks. Part B:
Cybernetics,” IEEE Trans. on Systems, Man, and Cybernetics, 29, No. 6, 674–685 (1999).
20. O. G. Rudenko and A. A. Bessonov, “Robust training of wavelet neural networks,” Probl. Upravl. Inf., No. 5, 66–79
(2010).
21. O. G. Rudenko and A. A. Bessonov, “Robust training of radial basis networks,” Cybernetics and Systems Analysis,
47, No. 6, 863–870 (2011).
22. O. Rudenko and O. Bezsonov, “Function approximation using robust radial basis function networks,” J. of Intelligent
Learning Systems and Appl., 3, 17–25 (2011).
23. O. G. Rudenko and A. A. Bessonov, “M-training of radial basis networks using asymmetric influence functions,”
Probl. Upravl. Inf., No. 1, 79–93 (2012).
182
